Project Overview
项目概览
This project implements a complete audio analysis pipeline that takes a music file as input and produces comprehensive analytical reports with rich visualizations. It covers the full workflow from audio loading and preprocessing to feature extraction, machine learning-based classification, and publication-quality chart generation.
本项目实现了一套完整的音频分析管道,以音乐文件为输入,输出包含丰富可视化的综合分析报告。覆盖从音频加载、预处理到特征提取、机器学习分类和出版级图表生成的全流程。
The system supports three execution modes — direct CLI, interactive file picker, and a Gradio-based web application deployed on Hugging Face Spaces.
系统支持三种运行模式:命令行直调、交互式文件选择器,以及部署在 Hugging Face Spaces 上的 Gradio Web 应用。
Technical Highlights
技术亮点
Full-Stack Audio Analysis Pipeline
全链路音频分析管道
The system implements a 6-step pipeline orchestrated by MusicSignalAnalyzer. Each step is encapsulated in a dedicated class with clean interfaces, making the architecture modular and extensible.
系统通过 MusicSignalAnalyzer 类编排 6 步分析管道。每个步骤封装在独立的类中,接口清晰,架构模块化且易于扩展。
Hybrid Instrument Classification
混合乐器分类器
Implements a dual-path instrument classifier that combines:
- Rule-based classification: Frequency-domain heuristic rules (spectral centroid, bandwidth, zero-crossing rate thresholds) for zero-dependency inference.
- ML classification: scikit-learn
RandomForestwithStandardScalernormalization, loading pre-trained.pklmodels at runtime. - Auto-fallback mechanism: Transparently falls back from ML to rules when the model is unavailable, ensuring the system always produces results.
Supports 7 instrument categories: Strings, Bass, Percussion, Wind, Keyboard, Vocal, and Unknown.
实现了双路径乐器分类器,结合两种方式:
- 基于规则的分类:基于频域启发式规则(频谱质心、带宽、过零率阈值)的零依赖推理。
- 机器学习分类:使用 scikit-learn 随机森林 + StandardScaler 标准化,运行时加载预训练模型。
- 自动回退机制:当 ML 模型不可用时自动回退到规则分类,确保系统始终产出结果。
支持 7 种乐器类别:弦乐、低音、打击乐、管乐、键盘、人声、未知。
Comprehensive Feature Extraction
全面的特征提取
14 distinct audio features extracted across three domains, all with descriptive statistics (mean, std, min, max, median):
跨三个域提取 14 种音频特征,所有特征均计算描述性统计量(均值、标准差、最小值、最大值、中位数):
| Domain | 域 | Features | 特征 |
|---|---|---|---|
| Spectral | 频谱域 | Spectral Centroid / 质心, Bandwidth / 带宽, Rolloff / 滚降, Contrast / 对比度, Chroma / 色度 (12-bin), Tonnetz / 音网 (6-dim), STFT Spectrogram / 语谱图, Mel Spectrogram / 梅尔语谱图 | |
| Temporal | 时域 | RMS Energy / 均方根能量, Short-time Energy / 短时能量, Zero-Crossing Rate / 过零率 | |
| Cepstral | 倒谱域 | MFCC (13 coefficients / 梅尔频率倒谱系数), MFCC Delta / 一阶差分, MFCC Delta-2 / 二阶差分 | |
Melody Analysis with PYIN
基于 PYIN 的旋律分析
Uses the PYIN algorithm for robust monophonic pitch tracking:
- Pitch trajectory extraction (Hz → MIDI conversion)
- Musical key detection (all 12 keys, major/minor) via chroma energy analysis
- Interval statistics (mean, max, min in semitones)
- Dominant note extraction via windowed mode detection
- Melody similarity comparison via chroma correlation
使用 PYIN 算法进行鲁棒的单音高追踪:
- 音高轨迹提取(Hz → MIDI 转换)
- 通过色度能量分析检测调性(全部 12 个调,大调/小调)
- 音程统计(均值、最大值、最小值,单位半音)
- 通过滑窗众数检测提取主导音符
- 通过色度相关性比较旋律相似度
Cross-Platform Audio I/O
跨平台音频输入输出
Three-tier backend fallback architecture:
- soundfile — primary for WAV/FLAC
- audioread — primary for MP3/M4A/OGG (requires FFmpeg)
- librosa — universal fallback
Backend priority is automatically reordered based on file extension. Includes robust error handling with platform-specific FFmpeg installation guidance.
三层后端回退架构:
- soundfile — WAV/FLAC 首选后端
- audioread — MP3/M4A/OGG 首选后端(需 FFmpeg)
- librosa — 通用兜底
后端优先级根据文件扩展名自动调整。包含健壮的错误处理和平台特定的 FFmpeg 安装指引。
Architecture
系统架构
Music_signal_analysis/ ├── main.py # CLI entry & MusicSignalAnalyzer orchestrator ├── run.py # One-click launcher with env/dependency checks ├── app.py # Gradio web interface (HF Spaces) ├── src/ │ ├── analysis/ │ │ ├── timbre_analysis.py # TimbreAnalyzer — spectral/cepstral/temporal │ │ ├── melody_extraction.py # MelodyExtractor — PYIN pitch, chroma, key │ │ └── instrument_classifier.py # InstrumentClassifier — hybrid ML + rules │ ├── utils/ │ │ └── audio_loader.py # AudioLoader — multi-backend audio I/O │ └── visualization/ │ └── visualizer.py # MusicVisualizer — charts + font management ├── models/ # Pre-trained ML models (optional) ├── tests/ # 82 test cases across 5 test files └── docs/ # Documentation
Music_signal_analysis/ ├── main.py # CLI 入口 & 分析调度器 ├── run.py # 一键启动器(含环境与依赖检查) ├── app.py # Gradio Web 界面(HF Spaces 部署) ├── src/ │ ├── analysis/ │ │ ├── timbre_analysis.py # 音色分析器 — 频谱/倒谱/时域特征 │ │ ├── melody_extraction.py # 旋律提取器 — PYIN 音高、色度、调性 │ │ └── instrument_classifier.py # 乐器分类器 — ML + 规则混合 │ ├── utils/ │ │ └── audio_loader.py # 音频加载器 — 多后端音频读写 │ └── visualization/ │ └── visualizer.py # 可视化器 — 图表生成 + 字体管理 ├── models/ # 预训练模型(可选) ├── tests/ # 5 个文件 82 个测试用例 └── docs/ # 文档
Design Principles:
- Modular: Each analysis domain is an independent, testable module.
- Robust: Multi-backend fallback at every level (audio loading, classification, font rendering).
- Extensible: New feature extractors or classifiers can be added without modifying the pipeline.
设计原则:
- 模块化:每个分析域都是独立可测试的模块。
- 健壮性:每一层都有多后端回退机制。
- 可扩展:新的特征提取器或分类器无需修改管道即可加入。
Visualization
可视化
The system generates 5 publication-quality charts per analysis run. All charts support Chinese labels with cross-platform font auto-detection and matplotlib cache management.
每次分析生成 5 张出版级图表。所有图表支持中文标签,具备跨平台字体自动检测和 matplotlib 缓存管理。
| Chart | 图表 | Type | 类型 | Description | 描述 |
|---|---|---|---|---|---|
| Timbre Analysis | 音色分析 | 3×2 composite | 3×2 综合图 | Spectrogram, MFCC, Spectral Centroid, Bandwidth, Chroma, ZCR | 语谱图、MFCC、频谱质心、带宽、色度、过零率 |
| Melody Analysis | 旋律分析 | 2×2 composite | 2×2 综合图 | Pitch trajectory, Normalized contour, Chroma, Amplitude | 音高轨迹、归一化轮廓、色度、振幅 |
| Spectrogram | 语谱图 | Single | 单图 | STFT magnitude in dB (viridis) | STFT 幅度(分贝) |
| Chroma Features | 色度特征 | Single | 单图 | 12 pitch-class heatmap (BuPu) | 12 音级热力图 |
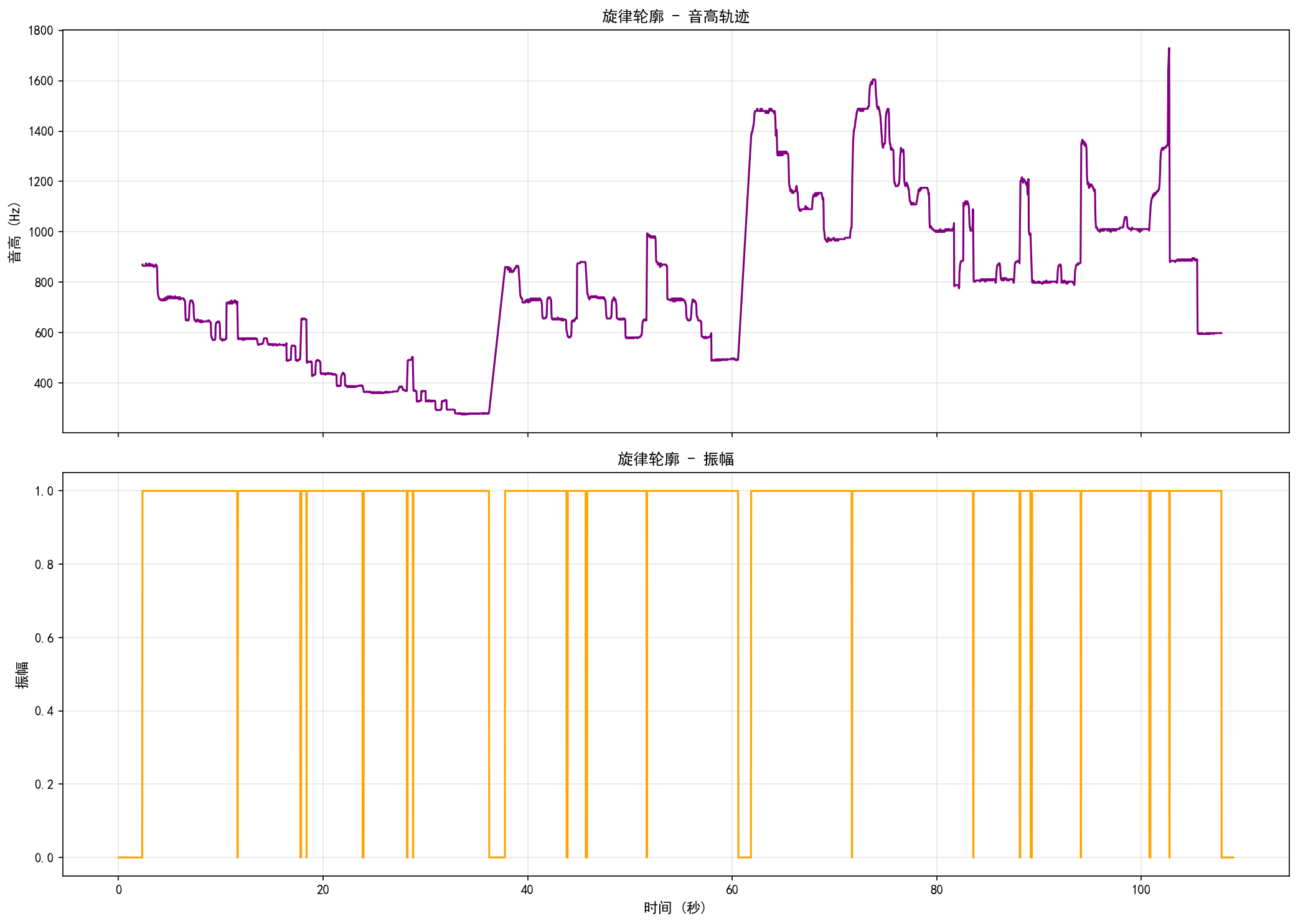
| Melody Contour | 旋律轮廓 | 2-panel | 双面板 | Pitch trajectory + Amplitude over time | 音高轨迹 + 振幅随时间变化 |
Output Examples
输出示例
Real analysis results from a WAV music sample. Click any image to view full size.
WAV 音乐样本的真实分析结果。点击任意图片查看大图。
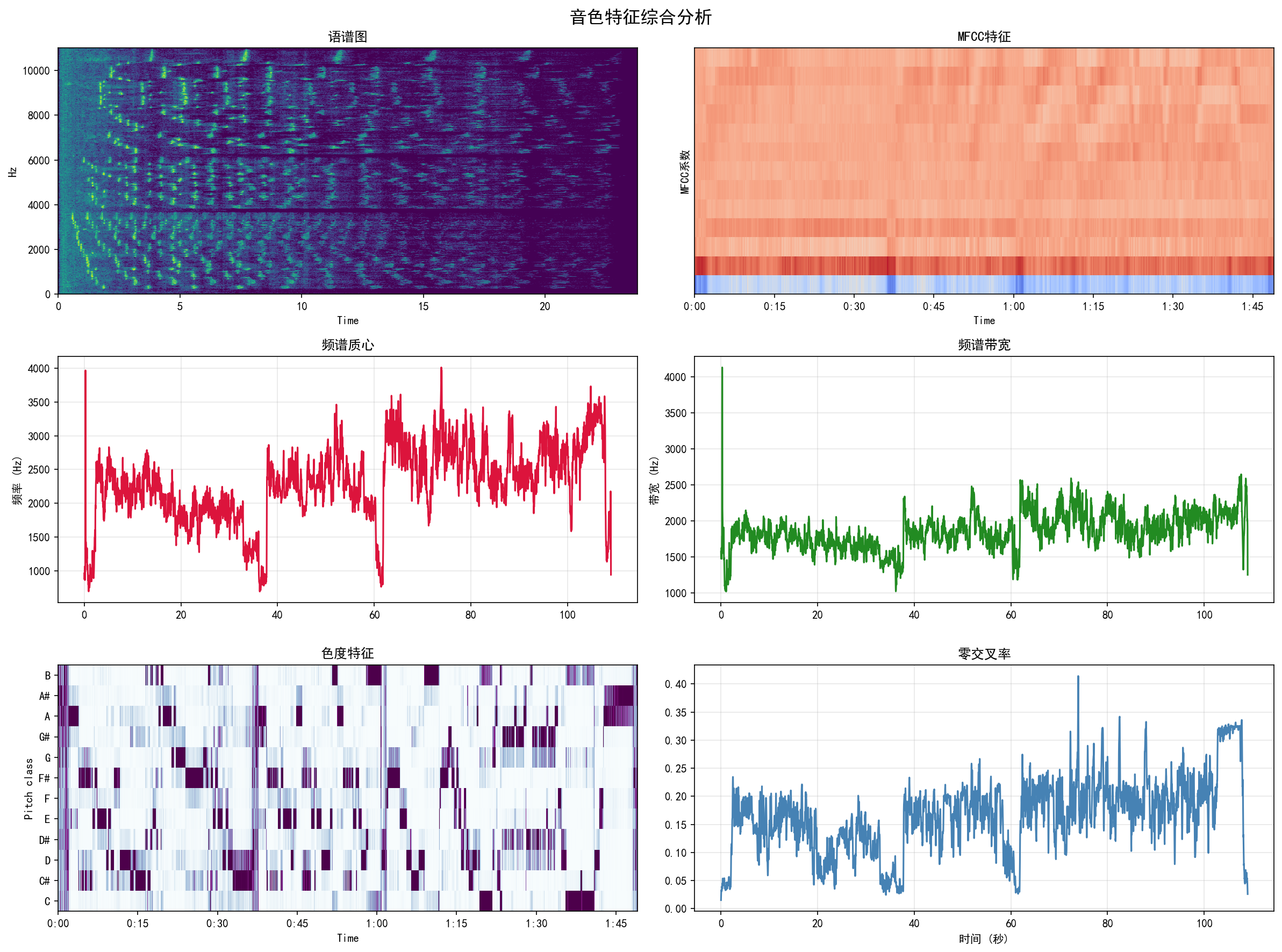
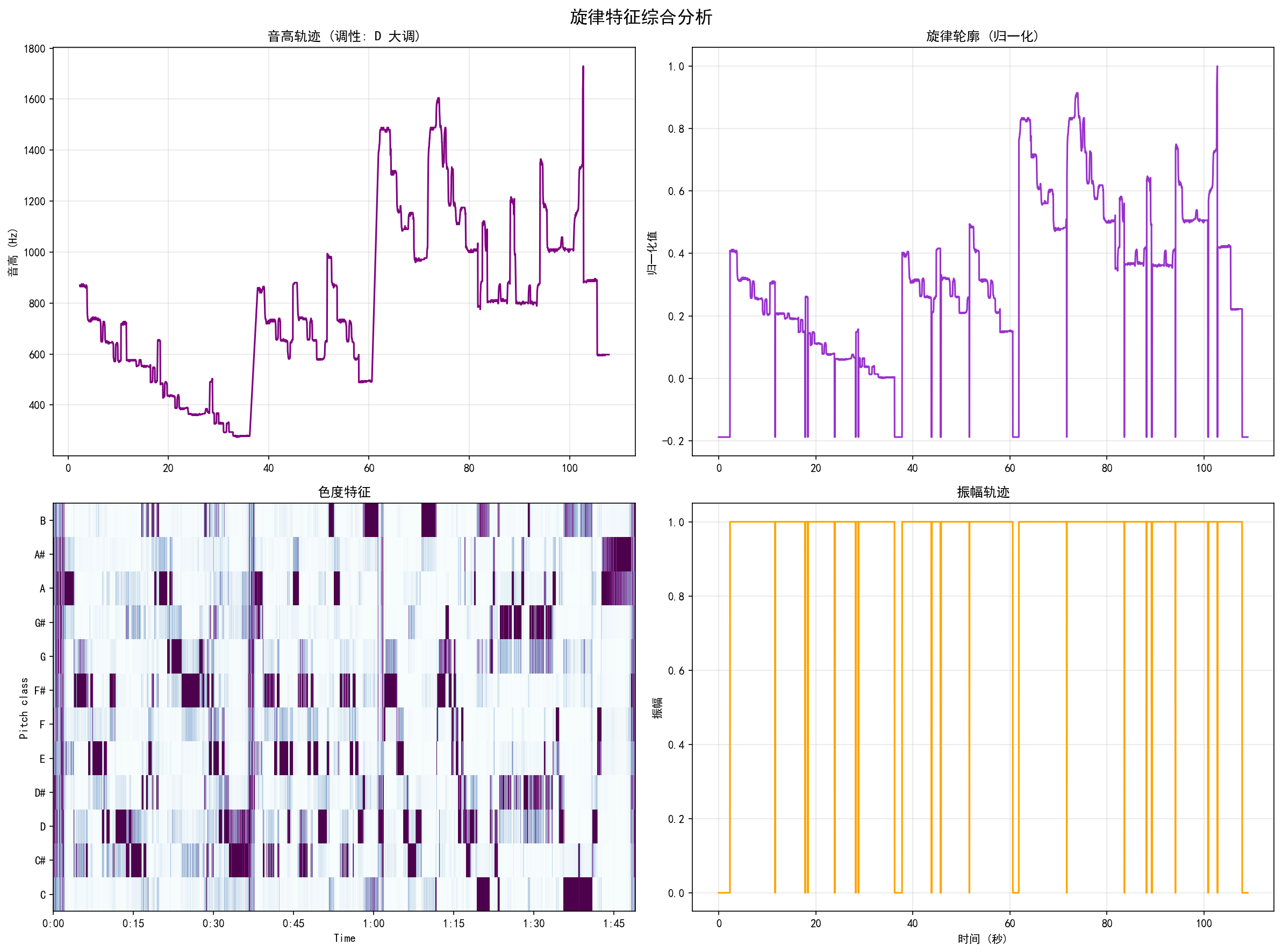
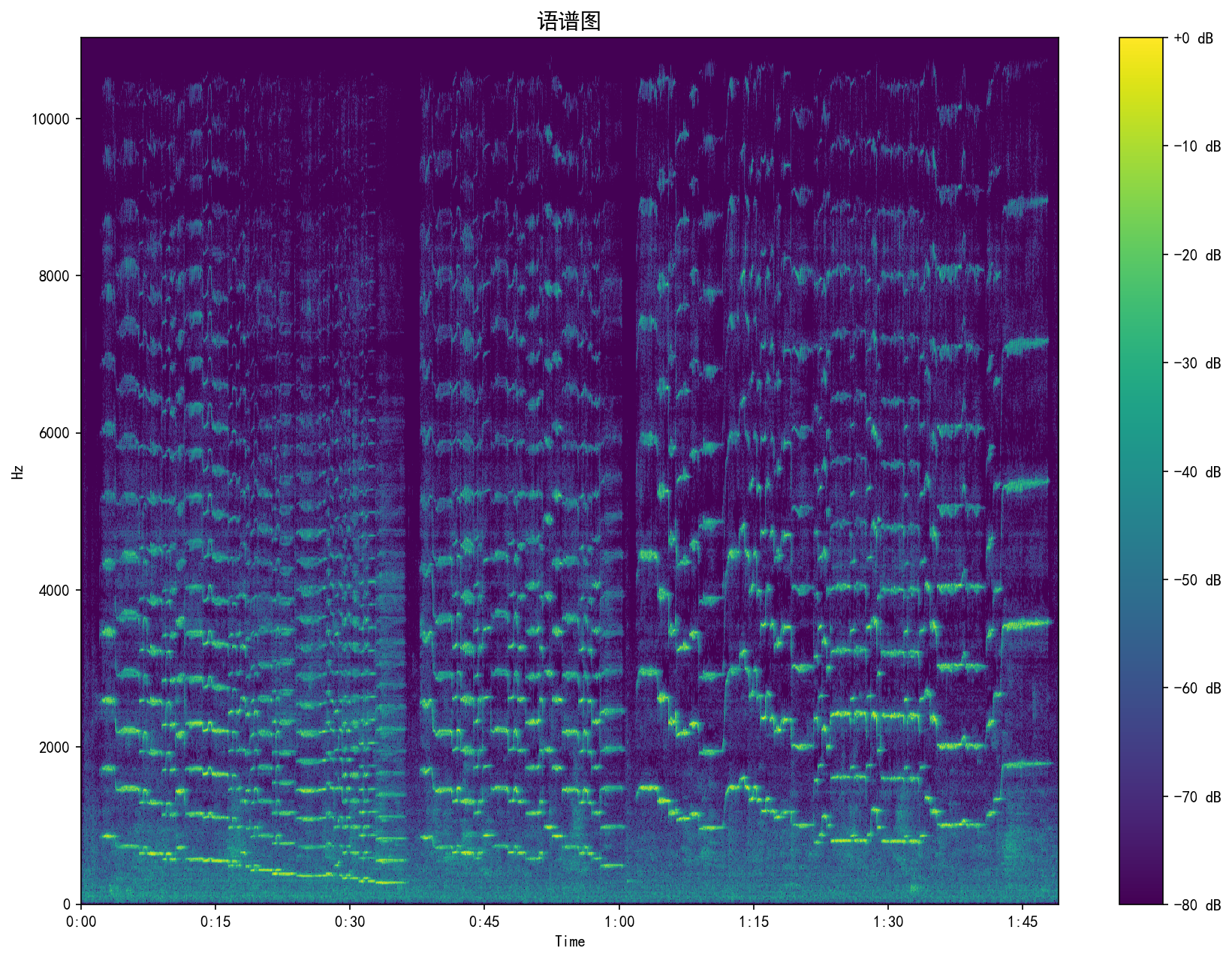
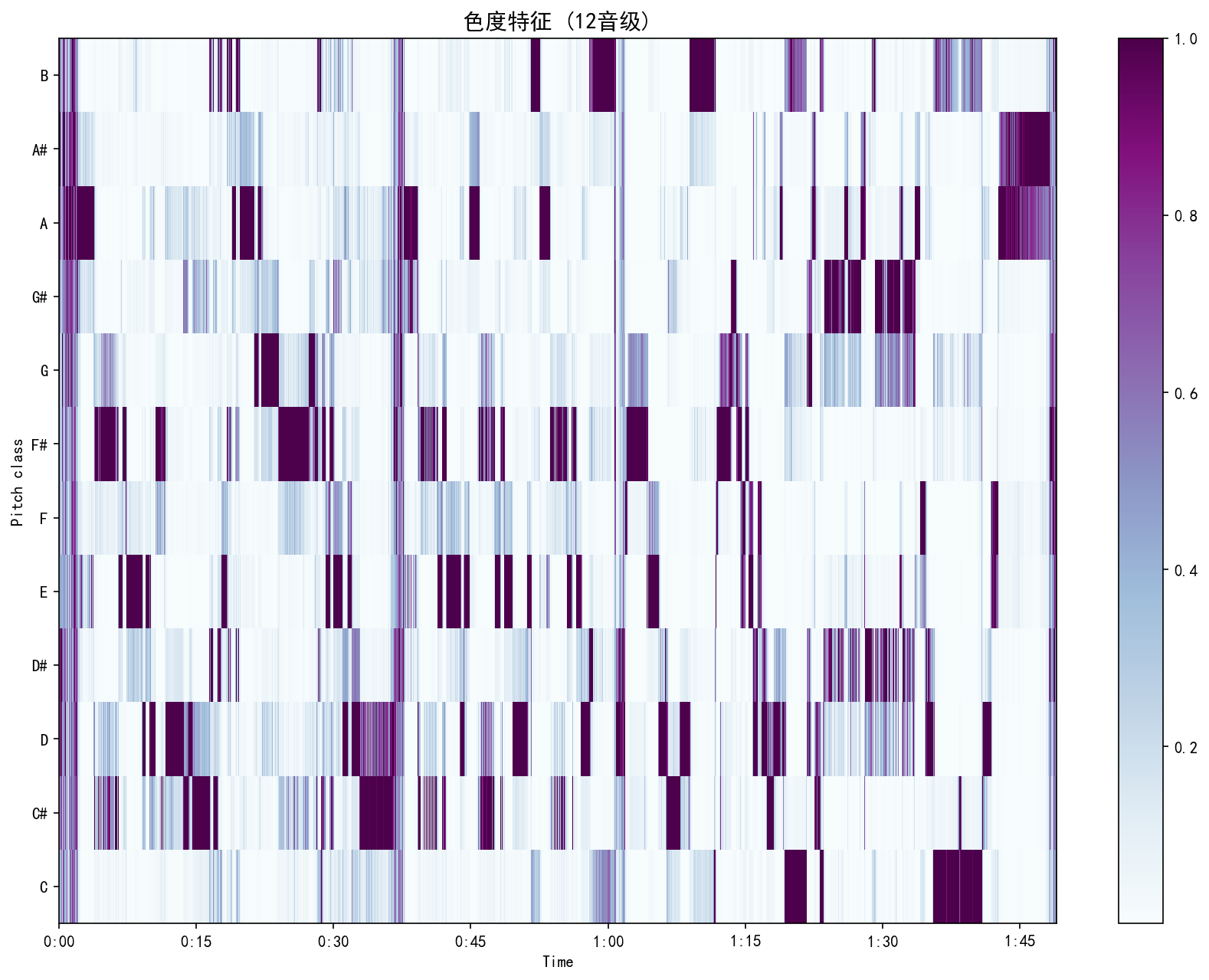
Web Deployment
Web 部署
Deployed as a Gradio application on Hugging Face Spaces (free tier):
以 Gradio 应用形式部署在 Hugging Face Spaces(免费层):
| URL | LunarStar6564168/music-signal-analysis | ||
| Interface | 界面 | Upload audio → Configure parameters → View results | 上传音频 → 配置参数 → 查看结果 |
| Infrastructure | 基础设施 | 2 vCPU / 16 GB RAM / 50 GB ephemeral disk | 2 vCPU / 16 GB RAM / 50 GB 临时磁盘 |
| System Deps | 系统依赖 | FFmpeg + CJK fonts via packages.txt | |
Testing
测试
82 test cases covering all core modules with pytest. Shared fixtures generate synthetic audio (440 Hz sine wave) for reproducible, isolated testing.
使用 pytest 编写 82 个测试用例,覆盖所有核心模块。共享测试夹具生成合成音频(440 Hz 正弦波),确保测试可复现且相互隔离。
| Module | 模块 | Tests | 用例数 | Key Coverage | 主要覆盖 |
|---|---|---|---|---|---|
| AudioLoader | 音频加载器 | 15 | Multi-backend loading, resampling, preprocessing, batch ops, error hints | 多后端加载、重采样、预处理、批量操作、错误提示 | |
| InstrumentClassifier | 乐器分类器 | 24 | Rule/ML paths, input validation, feature extraction, confidence scores | 规则/ML 路径、输入验证、特征提取、置信度 | |
| MelodyExtractor | 旋律提取器 | 16 | PYIN pitch range, chroma, contour normalization, key detection, similarity | PYIN 音高范围、色度、轮廓归一化、调性检测、相似度 | |
| TimbreAnalyzer | 音色分析器 | 11 | MFCC extraction, spectral/temporal features, statistics, similarity | MFCC 提取、频谱/时域特征、统计量、相似度 | |
| MusicVisualizer | 可视化器 | 16 | All 7 plot types, comprehensive reports, empty audio edge case | 全部 7 种图表、综合报告、空音频边界情况 |
Key Technologies
核心技术栈
| Category | 类别 | Technologies | 技术 |
|---|---|---|---|
| Audio Processing | 音频处理 | librosascipysoundfileaudioread | |
| Machine Learning | 机器学习 | scikit-learnRandomForestStandardScaler | |
| Visualization | 可视化 | matplotliblibrosa.display | |
| Web Framework | Web 框架 | Gradio | |
| Deployment | 部署 | Hugging Face SpacesDocker | |
| Testing | 测试 | pytestpytest-cov | |
| Numerics | 数值计算 | NumPy | |
Usage Examples
使用示例
CLI — Direct Mode
命令行 — 直调模式
python main.py input/music.wav python main.py input/music.wav --classify-mode rule -d 60
CLI — Interactive Mode
命令行 — 交互模式
python run.py # Scans input/ directory, presents numbered file picker
python run.py # 扫描 input/ 目录,展示编号文件选择菜单
Web Interface
Web 界面
Open https://huggingface.co/spaces/LunarStar6564168/music-signal-analysis Upload audio → Set parameters → Click "Start Analysis"
打开 https://huggingface.co/spaces/LunarStar6564168/music-signal-analysis 上传音频 → 设置参数 → 点击"开始分析"
Development History
开发历程
14 commits over a focused 2-week development cycle, demonstrating iterative refinement from core functionality to production deployment:
14 次提交,历时 2 周的集中开发,展示了从核心功能到生产部署的迭代演进:
- Core analysis pipeline (timbre + melody extraction)
- Comprehensive test suite (82 cases)
- Interactive CLI with one-click launcher
- Cross-platform audio loading (MP3/M4A/OGG support)
- Hybrid instrument classifier (rules + ML)
- Gradio web interface + Hugging Face Spaces deployment
- Cross-platform Chinese font rendering for containers
- 核心分析管道(音色 + 旋律提取)
- 完善的测试套件(82 个用例)
- 交互式命令行 + 一键启动器
- 跨平台音频加载(MP3/M4A/OGG 支持)
- 混合乐器分类器(规则 + ML)
- Gradio Web 界面 + Hugging Face Spaces 部署
- 容器化环境跨平台中文字体渲染
What I Learned
收获与成长
- Audio Signal Processing: Deep understanding of MFCC, STFT, spectral features, and the PYIN pitch estimation algorithm through hands-on implementation.
- ML in Production: Designing a hybrid classifier with graceful fallback, feature normalization, and model serialization with joblib.
- Robustness Engineering: Building multi-backend fallback systems (audio I/O, font rendering, classification) that degrade gracefully rather than fail.
- Test-Driven Development: Writing 82 tests with synthetic audio fixtures for deterministic, reproducible testing of signal processing code.
- Web Deployment: Packaging a scientific Python application for free cloud deployment, managing system dependencies (FFmpeg, CJK fonts) in containerized environments.
- 音频信号处理:通过动手实现深入理解 MFCC、STFT、频谱特征和 PYIN 音高估计算法。
- 机器学习工程化:设计具有优雅回退、特征归一化和模型序列化的混合分类器。
- 健壮性工程:构建多层后端回退系统,优雅降级而非直接报错。
- 测试驱动开发:使用合成音频夹具编写 82 个测试,确保信号处理代码的确定性和可复现性。
- Web 部署:将科学计算 Python 应用打包为免费云端部署,在容器化环境中管理系统依赖。