
GRPO简介
GRPO(Group Relative Policy Optimization)由 DeepSeek 团队在 DeepSeekMath 论文中提出。它的核心作用是在不依赖 Critic 网络(价值模型)的情况下做强化学习——通过同一道题的多个回答互相比较来产生训练信号。这让训练更简单、更省显存,而且天然适合让模型探索不同的解法。最早用于数学推理(DeepSeekMath),后被广泛用于搜索 Agent(Search-R1)、代码生成等领域。
GRPO 优势计算公式:
策略更新(PPO clipped loss):
其中 R_i 是第 i 条轨迹的 reward,μ_group 和 σ_group 是同一题所有 G 条轨迹的均值和标准差,r 是新旧策略概率比,ε 防止更新幅度过大(通常 0.2)
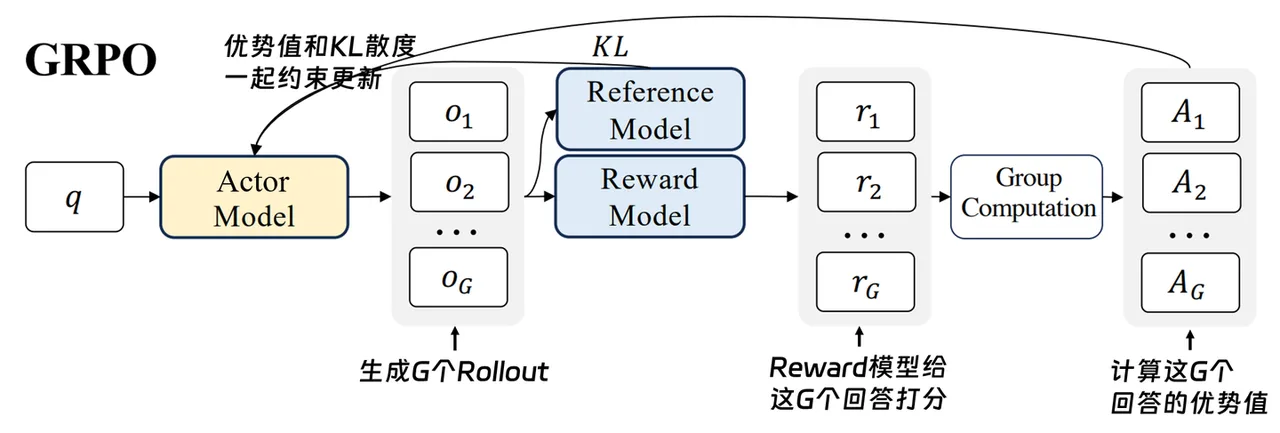
GRPO 的逻辑: 大家(Group)一起上——同一个问题独立回答多次,根据每份回答的表现为它打一个分数(reward),然后在组内算出互相的相对排名(Advantage)。比自己组平均水平好的就拿正分(被强化),差的就拿负分(被抑制)。但有三条规矩:一是奖励/惩罚别太激动(PPO clipped,防止一次更新步子太大),二是别丢了自己原来的语言底子(KL 约束不要偏离初始模型太远),三是同一个问题必须生成多个回答才能比较。
GRPO训练中涉及许多容易让人头晕眼花的关键量词:比如 batch_size(一次拿几道题)、G(每道题生成几个答案,即组大小)、step(一次完整的前向+反向+参数更新)、epoch(数据集全部过一遍的一个学习轮次),下面逐个拆解一下。
用背单词来比喻
你有 1000 个单词要背,计划背 15 遍。
单词总数 = 1000 个 → 数据集大小
每次看多少个 = 10 个 → batch_size
背完一遍需要 :1000 ÷ 10 = 100 次(step) → 每个 epoch 中的 step 数
计划背 15 遍 → total_epochs = 15
┌─────────────────────────────────────────────────┐
│ │
│ 每天背 10 个单词(batch),背完一次叫一步(step)
│ │
│ Day 1: 单词 001–010 ← step 1 │
│ Day 2: 单词 011–020 ← step 2 │
│ ... │
│ Day 100: 单词 991-1000 ← step 100 │
│ ↑ │
│ 背完一遍 = 1 epoch = 100 steps │
└─────────────────────────────────────────────────┘| 概念 | 比喻 | 公式 |
|---|---|---|
| batch_size | 每次看几个单词 | — |
| step | 背完一组 = 走了一步 | — |
| epoch | 1000 个全背完一遍 | 1 epoch = 数据集大小 ÷ batch_size 步 |
| total_epochs | 计划背几遍 | — |
| total_training_steps | 实际背到多少组就停 | — |
真实训练中往往用步数(step)说了算,epoch 只是参考。 就像你说”我计划背 15 遍,但如果背到第 1005 组停下来,实际可能只背了 3 遍”。
带入训练中
Batch( batch_size)
模型一次拿几道题。
batch_size = 4 # 每个 step 抽 4 道不同的题batch_size 决定RL训练中每个 step模型会拿到多少个独立的问题组。
对GRPO来说:4 个题 → 4 个独立的 advantage 计算 → 4 组梯度平均后更新模型。
大 batch 的好处:偶尔碰上一道所有人全答错的难题,不会让整个 step 的梯度报废——因为还有其他题的信号在。
小 batch 的坏处:如果只有 1 道题,碰巧这道题所有 G 条轨迹全答错了,这个 step 的 advantage 全为 0,白跑一步。
G(num_generations / n_agent)
每道题生成几个答案。
G = 8 # 同一道题,让模型独立生成 8 次同一个 prompt 输入模型 8 次,每次独立采样,得到 8 条不同的回答。这 8 条回答组成一个组,组内做相对比较。
G 大的好处:组内 μ 和 σ 的估计更稳定,advantage 信号更可靠。
G 小的坏处:4 条轨迹的统计量太吵。可能 4 条全一样(instruct 模型的低熵更容易导致这样)→ 组内 σ=0 → advantage 全零 → 无效梯度。
Step
一次完整的”生成 → 算 reward → 更新参数”。
一个 step 做了:
1. 从数据集随机抽 batch_size 道题
2. 每道题生成 G 条回答(共 batch_size × G 条)
3. 每条回答算 reward
4. 按题目分组,组内算 GRPO advantage
5. 所有 batch_size × G 个 (log_prob, advantage) 对
→ 算 PPO clipped loss → 反向传播 → 更新参数每个 step 模型参数通过反向传播更新一次。
Epoch
数据集的所有题全部被模型看过一遍。
1 epoch = 数据集大小 ÷ batch_size (单位:steps)
例如:数据集 2000 道题,batch_size=4
→ 1 epoch = 2000 ÷ 4 = 500 个 step
→ total_epochs = 3 → 最多跑 1500 个 step在 GRPO 中,epoch 只是概念上的——模型不是在”学数据”,而是在”根据 reward 调整行为”。所以论文中通常不放 epoch 轴,直接放 step 轴。
total_training_steps
一般用作硬性停止条件。 跑够这个步数就停,不管 epoch 跑了几个。
total_training_steps = 1000 # 到 1000 步必定停止
total_epochs = 15 # 兜底上限,不会跑到通常 total_training_steps 先到。
一个具体例子
配置:batch_size=4, G=8, 数据集 2000 题, total_training_steps=1000
Step 1:
抽 4 道题(题 42, 题 817, 题 3, 题 156)
每道题生成 8 个答案 → 共 32 个答案
分组算 advantage → 4 组
PPO loss → backward → 更新参数
Step 2:
再抽 4 道题(题 991, 题 201, 题 74, 题 633)
...
Step 500:
数据集 2000 题抽了 2000 次(每道平均被抽到一次)
→ 1 epoch 完成
Step 1000:
total_training_steps 到达 → 训练停止
实际跑了 1000 ÷ 500 = 2 个 epoch如何选这些参数
| 参数 | 太小会怎样 | 太大代价 | 经验建议 |
|---|---|---|---|
| batch_size | 单步结果被个别难题支配,梯度不稳 | 显存放不下 | 至少 2-4,GPU 允许则 8+ |
| G | 组内方差为 0,advantage 无信号 | 生成时间线性增长 | instruct 模型至少 8,base 模型 4-5 即可 |
| steps | 模型没学会就停了 | 浪费算力(收敛后 plateau) | 先跑 500 步看趋势,再决定是否加 |
| epochs | 数据没充分利用 | GRPO 不太怕过拟合,但有上限 | 通常 2-5 个 epoch 也够了 |
其他相关概念
- total_training_steps vs total_epochs:前者是硬上限,后者是兜底。两个同时设时,先到的生效。
- micro_batch_size:在前向/反向传播时,把一个大的 batch 切分成更小的 micro batch 处理,用于节省显存。
- gradient_accumulation:跑好几个 micro batch 的前向后才做一次反向传播,模拟更大的 batch。