
Temperature 的数学本质
LLM 在输出下一个 token 的时候,首先会给自己词汇表中的每个 token 打出“适合作为下一个 token”的原始倾向分 logits,然后再用 Softmax 函数把 logits 转换成每个词被输出的概率(详见:✒️万字长文:LLM 后训练基础知识&常见“黑话”梳理 | Harry Yu),而 Temperature 就是加在这个 Softmax 函数 指数部分的一个分母。
假设模型为下一个 token 输出了一组原始倾向性分数(Logits):( 为 LLM 词汇表中的 token ID 总数)。
带 Temperature 的 Softmax 公式如下:
其中 (或 )就是 Temperature。
它会改变最终的输出概率分布
举个例子,假设 Logits(Transformer Softmax 之前的原始分数)是 [2.0, 1.0, 0.1](模型认为第一个 token 概率最大)。
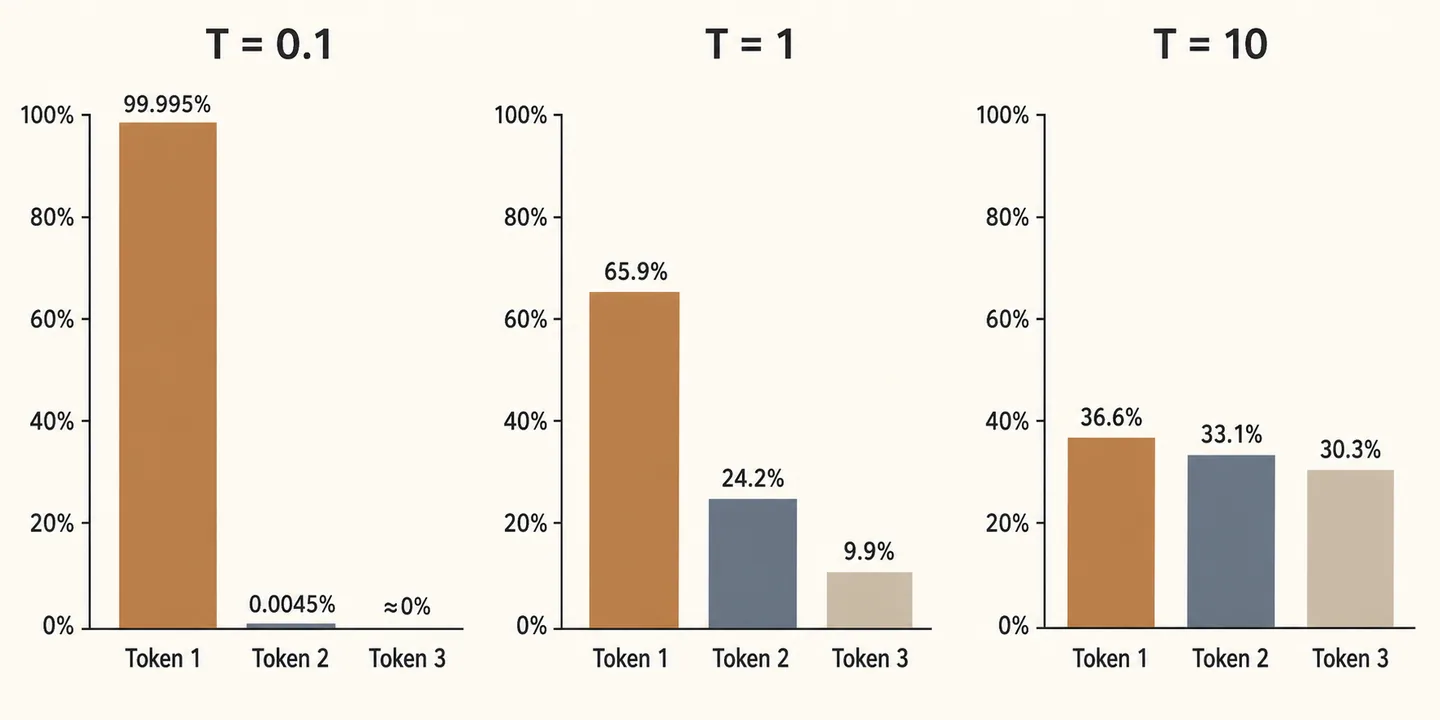
- 标准状态() 直接算 Softmax,保留原始的概率差异。
- 低温状态(,如 )
- 会变得很大(
20, 10, 1)。 - 效果:概率分布变得非常尖锐(Sharp)。最大的那个值的概率会无限接近 1,其他的无限接近 0。
- 对应现象:LLM 变得保守、确定、容易复读。
- 会变得很大(
- 高温状态(,如 )
- 会变得很小(
0.2, 0.1, 0.01)。 - 效果:概率分布变得非常平坦(Flat),趋向于均匀分布。
- 对应现象:LLM 变得随机、有创造力,但也容易胡说八道(幻觉)。
- 会变得很小(
LLM 推理输出时的 Temperature
这是最常听到的场景,其原理在上一章节已简单讲述,主要作用于 LLM 根据概率进行输出选词的阶段,不会影响模型本身。
- 作用:控制模型输出的“创造性”与“准确性”。
- 例子:
- 写代码/做数学题:我们需要唯一的正确答案,所以把 设得很低(如 0 或 0.2)。这时候模型几乎总是选概率最高的那个词,像个严谨的机器人。
- 写小说/头脑风暴:我们需要多样性,把 设高(如 0.8 或 1.0)。这时候模型有机会选中那些“概率虽然不是第一,但也还不错”的词,从而写出意想不到的句子。
Loss Function 里的 τ(Contrastive Loss)
最典型的应用是在对比学习(Contrastive Learning)中,比如 SimCLR、MoCo 或者 OpenAI 的 CLIP 模型。它们使用的 Loss 叫做 InfoNCE Loss。
公式长这样(看分母里的 ):
这其实也是 Temperature 的一种应用(论文中一般也这么叫),虽然数学形式一样,但是这个参数会直接影响模型的训练阶段:
它控制模型对“困难样本”的挖掘程度(Hardness-aware property)。
- 当 很小(低温):
- Softmax 分布非常尖。这意味着,只有那些相似度非常高的样本(Hard Negatives,即长得很像正样本的负样本)才会产生较大的梯度。
- 作用:强迫模型去区分那些非常容易混淆的细节。模型会“死磕”那些最难区分的例子。
- 副作用:如果太小,可能会导致数值不稳定,或者模型过于关注噪点。
- 当 很大(高温):
- 分布变平。所有负样本(无论像不像)对 Loss 的贡献都差不多。
- 作用:模型学得比较“佛系”,梯度变得平滑,但学不到精细的特征。
总结一下 Contrastive Loss 里的 τ:
如果你发现模型分不清“哈士奇”和“狼”,你就把 调小一点。这会让 Loss 函数狠狠地惩罚模型,迫使它把这两个长得很像的东西拉开距离。
一张表总结
| 维度 | LLM 推理(Inference) | 对比学习 Loss(Training) |
|---|---|---|
| 符号 | 通常写作 Temperature() | 通常写作 (Tau) |
| 数学本质 | Softmax 的分母缩放因子 | Softmax 的分母缩放因子 |
| 调大(Hot) | 增加随机性,更多样,易幻觉 | 关注全局,梯度平滑,学习容易样本 |
| 调小(Cold) | 减少随机性,更确定,易复读 | 关注难例(Hard Negatives),学习细微特征 |
| 一句话 | 决定了模型怎么选词,和梯度无关 | 决定了模型怎么计算梯度 |
复读机与幻觉问题
LLMs 的“复读机问题”
定义:指模型倾向于重复它从训练数据中学到的、高频出现的、安全的模式或内容,缺乏真正的创造力、原创性和深入推理能力。它只是在“优化地复述”已知信息。
根本原因:
- 训练目标:LLMs 的核心训练目标(如下一个词预测)本质上是学习训练数据的概率分布。它的目标是以高概率生成“看起来正确”的文本,而不是追求“真实”或“创新”。
- 数据偏差:训练数据中高频、模式化的内容(如维基百科的说明文体、论坛的常见问答)被模型深刻学习,成为默认输出模式。
- 安全对齐:为了减少有害输出,RLHF 等对齐技术可能会让模型变得更加“保守”和“循规蹈矩”,加剧复读机倾向。
你可以把“复读机问题”理解为模型的“过度保守”缺陷。
LLMs 的“幻觉”问题
定义:指模型生成的内容在事实上不正确、没有依据,或与提供的上下文/现实世界知识相矛盾,但模型以高度自信的方式呈现出来。
根本原因:
- 概率本质:模型生成的是“在语境中最可能出现的词序列”,而不是“经过验证的事实”。流畅性和概率优先于真实性。
- 知识边界:模型的知识是静态的、有截止日期的,且可能存在训练数据中的错误。它对“不知道”的认知能力很弱。
- 缺乏验证机制:生成过程中没有内置的事实核查或逻辑一致性检查步骤。
你可以把“幻觉”问题理解为模型的**“过度自信”或“创造性失控”**缺陷。
复读机问题与“幻觉”有什么联系?
虽然它们在表面上看起来不同(一个是像傻子一样重复,一个是像骗子一样胡说八道),但在底层机制上,它们存在一种“此消彼长”甚至“相互诱发”的关系。
Temperature 跷跷板效应
这是两者最直接的联系。我们在调节模型参数时,往往是在复读和幻觉之间找平衡。
- 低温度(Low Temperature)→ 易复读
- 为了让模型说话严谨、不胡编乱造(减少幻觉),我们通常会降低温度。
- 但温度过低,模型变得极其保守,只敢选概率最高的词。一旦陷入循环,它就没有“跳出循环”的随机性,从而导致复读机。
- 高温度(High Temperature)→ 易幻觉
- 为了打破复读,我们提高温度,增加随机性。
- 但随机性太高,模型就会开始“发散思维”,把不相关的概念拼凑在一起,导致一本正经地胡说八道(幻觉)。
结论:复读机是过于确定的病,幻觉是过于发散的病。